SkyHive is an end-to-end reskilling platform that automates abilities evaluation, determines future skill requirements, and fills ability spaces through targeted knowing suggestions and task chances. We deal with leaders in the area consisting of Accenture and Workday, and have actually been acknowledged as a cool supplier in human capital management by Gartner.
We have actually currently developed a Labor Market Intelligence database that shops:
- Profiles of 800 million (anonymized) employees and 40 million business
- 1.6 billion task descriptions from 150 nations
- 3 trillion special ability mixes needed for present and future tasks
Our database consumes 16 TB of information every day from task posts scraped by our web spiders to paid streaming information feeds. And we have actually done a great deal of intricate analytics and artificial intelligence to obtain insights into worldwide task patterns today and tomorrow.
Thanks to our ahead-of-the-curve innovation, great word-of-mouth and partners like Accenture, we are growing quick, including 2-4 business consumers every day.
Driven by Information and Analytics
Like Uber, Airbnb, Netflix, and others, we are interfering with a market– the worldwide HR/HCM market, in this case– with data-driven services that consist of:
- SkyHive Ability Passport— a web-based service informing employees on the task abilities they require to develop their professions, and resources on how to get them.
- SkyHive Business— a paid control panel (listed below) for executives and HR to examine and drill into information on a) their staff members’ aggregated task abilities, b) what abilities business require to be successful in the future; and c) the abilities spaces.
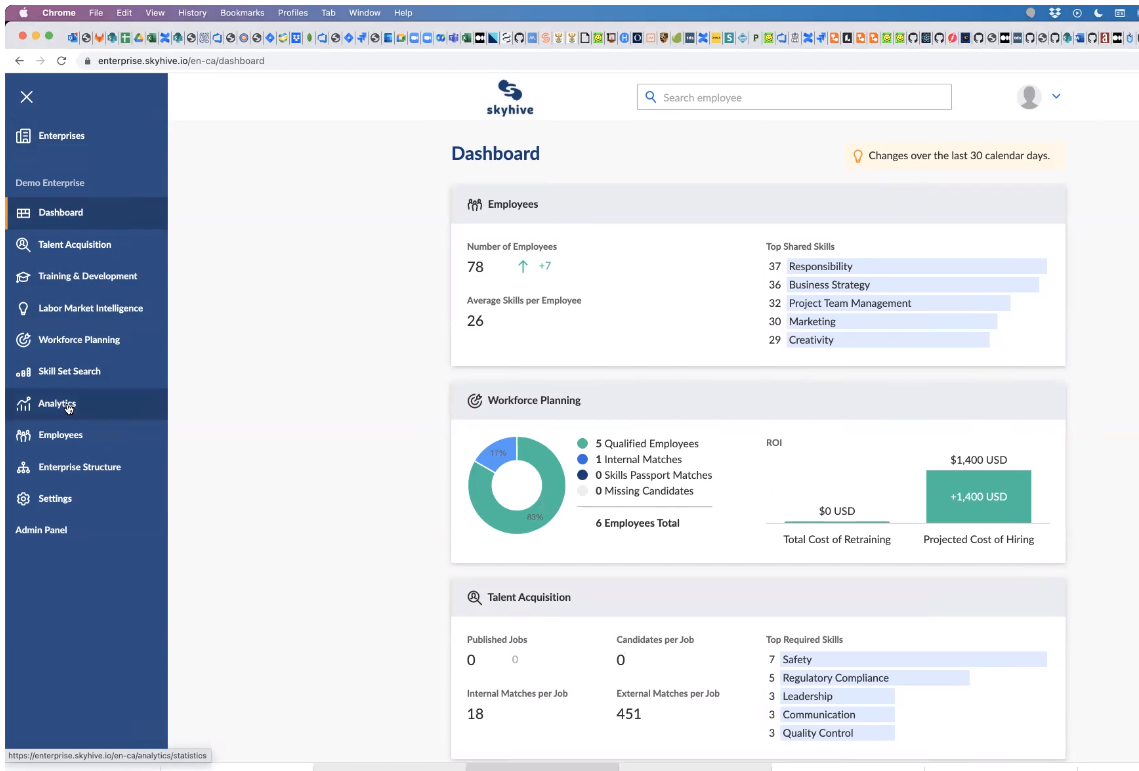
- Platform-as-a-Service through APIs— a paid service permitting services to use much deeper insights, such as contrasts with rivals, and hiring suggestions to fill abilities spaces.
Difficulties with MongoDB for Analytical Queries
16 TB of raw text information from our web spiders and other information feeds is disposed daily into our S3 information lake That information was processed and after that filled into our analytics and serving database, MongoDB.

MongoDB inquiry efficiency was too sluggish to support intricate analytics including information throughout tasks, resumes, courses and various geographics, specifically when inquiry patterns were not specified ahead of time. This made multidimensional inquiries and signs up with sluggish and expensive, making it difficult to offer the interactive efficiency our users needed.
For instance, I had one big pharmaceutical client ask if it would be possible to discover all of the information researchers worldwide with a scientific trials background and 3+ years of pharmaceutical experience. It would have been an exceptionally costly operation, however naturally the client was searching for instant outcomes.
When the client asked if we might broaden the search to non-English speaking nations, I needed to describe it was beyond the item’s present abilities, as we had issues stabilizing information throughout various languages with MongoDB.
There were likewise restrictions on payload sizes in MongoDB, along with other unusual hardcoded peculiarities. For example, we might not query Fantastic Britain as a nation.
All in all, we had considerable difficulties with inquiry latency and getting our information into MongoDB, and we understood we required to transfer to something else.
Real-Time Data Stack with Databricks and Rockset
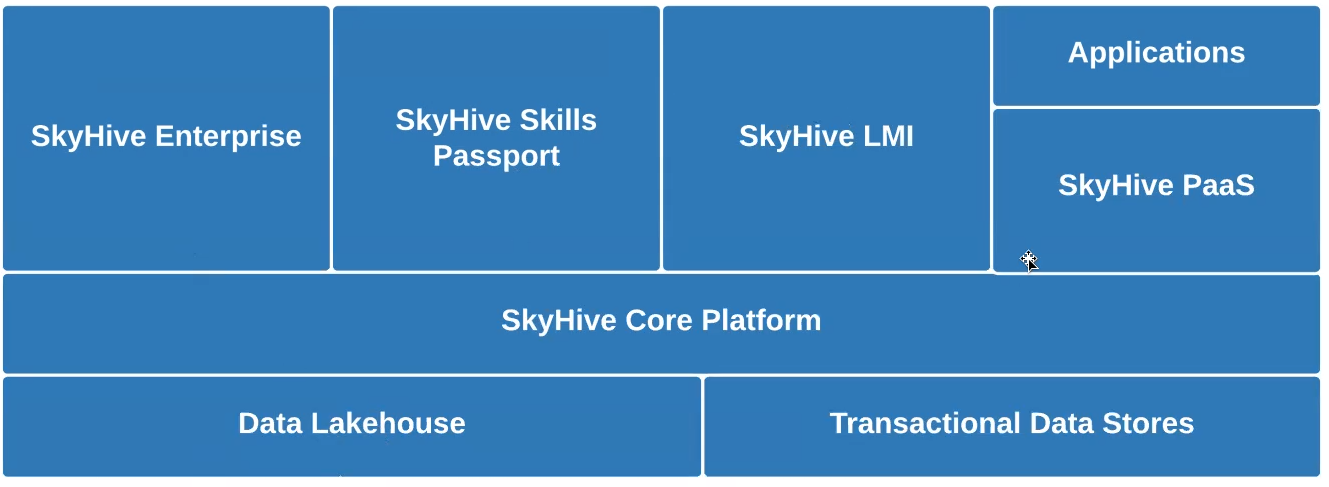
We required a storage layer efficient in massive ML processing for terabytes of brand-new information daily. We compared Snowflake and Databricks, selecting the latter due to the fact that of Databrick’s compatibility with more tooling choices and assistance for open information formats. Utilizing Databricks, we have actually released (listed below) a lakehouse architecture, saving and processing our information through 3 progressive Delta Lake phases. Crawled and other raw information lands in our Bronze layer and consequently goes through Glow ETL and ML pipelines that fine-tune and enhance the information for the Silver layer. We then develop grainy aggregations throughout numerous measurements, such as geographical area, task function, and time, that are saved in the Gold layer.

We have SLAs on inquiry latency in the low numerous milliseconds, even as users make complex, multi-faceted inquiries. Glow was not developed for that– such inquiries are dealt with as information tasks that would take 10s of seconds. We required a real-time analytics engine, one that develops an uber-index of our information in order to provide multidimensional analytics in a heart beat.
We selected Rockset to be our brand-new user-facing serving database. Rockset continually integrates with the Gold layer information and immediately develops an index of that information. Taking the grainy aggregations in the Gold layer, Rockset inquiries and signs up with throughout numerous measurements and carries out the finer-grained aggregations needed to serve user inquiries. That allows us to serve: 1) pre-defined Inquiry Lambdas sending out routine information feeds to consumers; 2) advertisement hoc free-text searches such as “What are all of the remote tasks in the United States?”
Sub-Second Analytics and Faster Iterations
After a number of months of advancement and screening, we changed our Labor Market Intelligence database from MongoDB to Rockset and Databricks. With Databricks, we have actually enhanced our capability to deal with substantial datasets along with effectively run our ML designs and other non-time-sensitive processing. On the other hand, Rockset allows us to support intricate inquiries on massive information and return responses to users in milliseconds with little calculate expense.
For example, our consumers can look for the leading 20 abilities in any nation worldwide and get outcomes back in near actual time. We can likewise support a much greater volume of client inquiries, as Rockset alone can deal with countless inquiries a day, despite inquiry intricacy, the variety of concurrent inquiries, or abrupt scale-ups somewhere else in the system (such as from bursty inbound information feeds).
We are now quickly striking all of our client SLAs, including our sub-300 millisecond inquiry time warranties. We can offer the real-time responses that our consumers require and our rivals can not match. And with Rockset’s SQL-to-REST API assistance, providing query outcomes to applications is simple.
Rockset likewise accelerates advancement time, enhancing both our internal operations and external sales. Formerly, it took us 3 to 9 months to develop an evidence of principle for consumers. With Rockset functions such as its SQL-to-REST-using-Query Lambdas, we can now release control panels tailored to the potential client hours after a sales demonstration.
We call this “item day absolutely no.” We do not need to offer to our potential customers any longer, we simply ask to go and attempt us out. They’ll find they can communicate with our information without any obvious hold-up. Rockset’s low ops, serverless cloud shipment likewise makes it simple for our designers to release brand-new services to brand-new users and client potential customers.

We are preparing to even more simplify our information architecture (above) while broadening our usage of Rockset into a number of other locations:
- geospatial inquiries, so that users can browse by focusing and out of a map;
- serving information to our ML designs.
Those jobs would likely happen over the next year. With Databricks and Rockset, we have actually currently changed and developed out a lovely stack. However there is still far more space to grow.