
Like many wide corporations, LinkedIn relied at the Lamba structure to run separate batch and streaming workloads, with a type of reconciliation on the finish. After enforcing Apache Beam, it used to be in a position to mix batch and streaming workloads, thereby slashing its processing time via 94%, the corporate says.
LinkedIn is a huge consumer of Apache Samza, a dispensed movement processing engine that the corporate evolved in-house in Scala and Java, along the Apache Kafka message bus. The corporate makes use of Samza to procedure 2 trillion messages in keeping with day, writes LinkedIn Senior Instrument Engineer Yuhong Cheng in a March 23 submit to the corporateâs engineering weblog.
It additionally is a huge consumer of Apache Spark, the preferred dispensed knowledge processing engine. LinkedIn makes use of Spark to run wide batch jobs, together with analytics, knowledge science, gadget finding out, A/B batch, and metrics reporting, in opposition to petabytes of knowledge.
Some use instances at LinkedIn required each real-time and batch features. As an example, it had to standardize the method of mapping consumer inputs (similar to process titles, talents, or instructional historical past) into a collection of pre-defined IDs that adhere to the corporateâs taxonomies. As soon as standardized, this information may well be used for seek indexing or working advice fashions, Cheng writes.
âActual-time computation is had to mirror the fast consumer updates,â she writes. âIn the meantime, we want periodic backfilling to redo standardization when new fashions are presented.â
LinkedInâs standardization workflow submit Beam (Symbol courtesy LinkedIn)
LinkedIn coded each the real-time and batch workloads in Samza, using the well-worn Lamba structure. Then again, the corporate encountered a lot of difficulties with this means. For starters, the engine used to be lower than the duty of powering the backfilling process, which had to standardize 40,000 member profiles in keeping with 2d, Cheng writes. It used to be additionally proving tricky to handle two other codebases and two other tech stacks.
âEngineers would want to be conversant in other languages and enjoy two finding out curves,â she writes. âIf there have been any problems, engineers would additionally want to achieve out to other infra groups for enhance.â
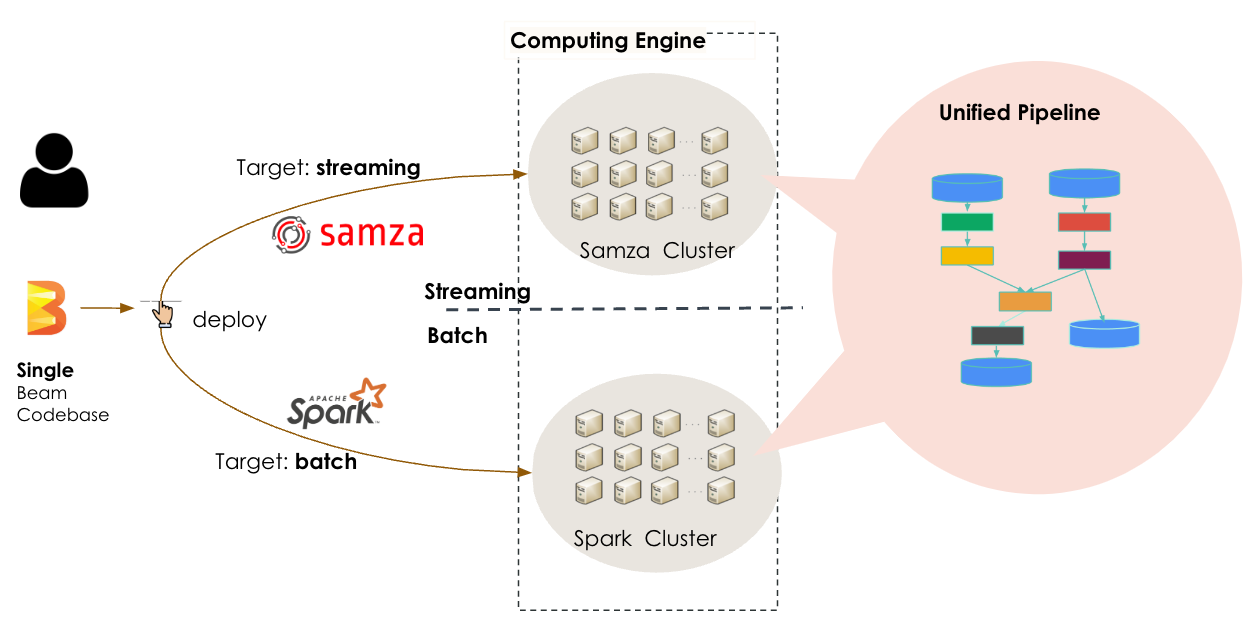
LinkedInâs resolution used to be to put in force Apache Spark to deal with the batch workload. Then again, as a substitute of writing working separate Samza and Spark systems to deal with those duties, the corporate elected to make use of Samza and Spark ârunnersâ running inside the Apache Beam framework, Cheng writes.
Apache Beam is a programming and runtime framework evolved via Google to unified batch and streaming paradigms. The framework, which changed into a Most sensible Degree Venture on the Apache Instrument Basis in 2017, strains its roots again to Googleâs preliminary MapReduce device and in addition mirrored parts of Google Cloud Dataflow, the corporateâs present parallel computational paradigm.
Standardization workload processing time and useful resource utilization ahead of and after Beam (Symbol courtesy LinkedIn)
Like Google, LinkedIn has struggled to construct large-scale knowledge processing programs that may rise up below the burden of big knowledge units but in addition face up to the technical complexity inherent in those programs. Because it used to be launched, Beam has presented the prospective to be a simplifying agent for each the improvement and the runtime.
âBuilders most effective want to expand and handle a unmarried codebase written in Beam,â she writes. âIf the objective processing is a real-time one, the process is deployed via Samza Cluster as a streaming process. If the objective processing is a backfilling process, the process is deployed via Spark Cluster as a batch process. This unified streaming and batch structure allows our group to benefit from each computing engines whilst minimizing construction and upkeep efforts.â
The corporate is figuring out really extensive beneficial properties in compute efficiency because of the transfer to Apache Beam. Cheng writes:
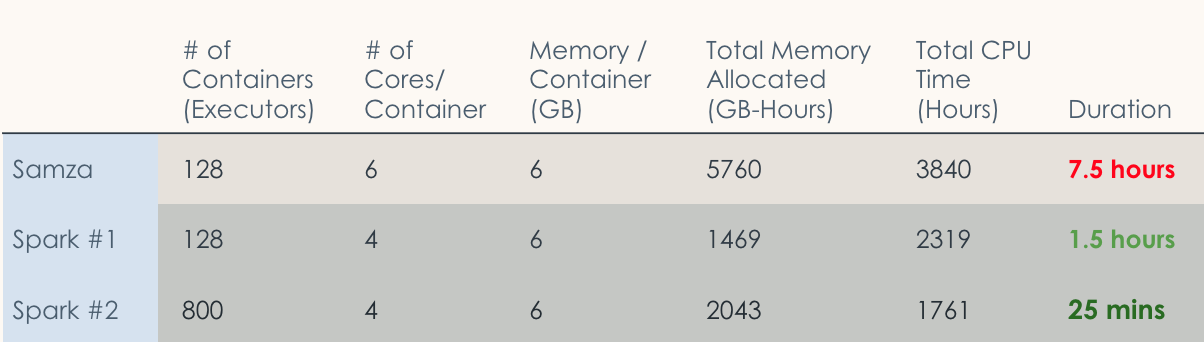
âAfter we ran backfilling as a streaming process, the whole reminiscence allotted used to be over 5,000 GB-Hours and the whole CPU time used to be just about 4,000 hours. After migrating to a Beam unified pipeline, working the similar good judgment as a batch process, the reminiscence allotted and CPU time each had been lower in part. The period additionally dropped considerably after we ran backfilling the use of Beam unified pipelines â from seven hours to twenty-five mins.â
All informed, the compute time used to be lowered via 94%-a whopping 20x growth. Since the Spark batch atmosphere is greater, the whole useful resource utilization dropped most effective 50%, in keeping with LinkedIn.
LinkedIn is inspired via Beamâs potency and plans to make use of it someday because it strikes to an âend-to-end convergenceâ of batch and streaming workloads. The corporate is now having a look to take on one of the demanding situations that exist when operating in streaming (Kafka) and batch (HDFS) environments.
Comparable Pieces:
Google/ASF Take on Large Computing Business-Offs with Apache Beam 2.0
Apache Beamâs Formidable Purpose: Unify Large Knowledge Building
Google Lauds Outdoor Affect on Apache Beam