Construction fashions that remedy a various set of duties has change into a dominant paradigm within the domain names of imaginative and prescient and language. In herbal language processing, vast pre-trained fashions, reminiscent of PaLM, GPT-3 and Gopher, have demonstrated outstanding zero-shot finding out of recent language duties. In a similar way, in laptop imaginative and prescient, fashions like CLIP and Flamingo have proven powerful efficiency on zero-shot classification and object reputation. A herbal subsequent step is to make use of such gear to build brokers that may entire other decision-making duties throughout many environments.
Alternatively, practicing such brokers faces the inherent problem of environmental variety, since other environments perform with distinct state motion areas (e.g., the joint area and steady controls in MuJoCo are essentially other from the picture area and discrete movements in Atari). This environmental variety hampers wisdom sharing, finding out, and generalization throughout duties and environments. Moreover, it’s tough to build praise purposes throughout environments, as other duties typically have other notions of luck.
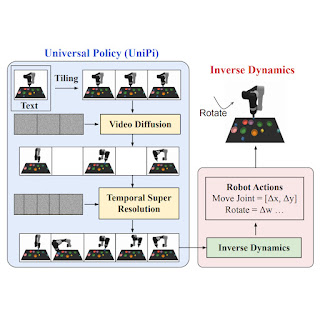
In âStudying Common Insurance policies by means of Textual content-Guided Video Eraâ, we recommend a Common Coverage (UniPi) that addresses environmental variety and praise specification demanding situations. UniPi leverages textual content for expressing project descriptions and video (i.e., picture sequences) as a common interface for conveying motion and statement conduct in numerous environments. Given an enter picture body paired with textual content describing a present target (i.e., the following high-level step), UniPi makes use of a singular video generator (trajectory planner) to generate video with snippets of what an agentâs trajectory will have to seem like to reach that target. The generated video is fed into an inverse dynamics type that extracts underlying low-level keep an eye on movements, which can be then done in simulation or by way of an actual robotic agent. We display that UniPi permits using language and video as a common keep an eye on interface for generalizing to novel targets and duties throughout various environments.
 |
| Video insurance policies generated by way of UniPi. |
 |
| UniPi is also implemented to downstream multi-task settings that require combinatorial language generalization, long-horizon making plans, or internet-scale wisdom. Within the backside instance, UniPi takes the picture of the white robotic arm from the cyber web and generates video snippets in step with the textual content description of the target. |
UniPi implementation
To generate a sound and executable plan, a text-to-video type should synthesize a constrained video plan beginning on the present seen picture. We discovered it more practical to explicitly constrain a video synthesis type right through practicing (versus simplest constraining movies at sampling time) by way of offering the primary body of each and every video as particular conditioning context.
At a excessive point, UniPi has 4 main elements: 1) constant video era with first-frame tiling, 2) hierarchical making plans via temporal great decision, 3) versatile conduct synthesis, and four) task-specific motion adaptation. We give an explanation for the implementation and advantage of each and every element intimately beneath.
Video era via tiling
Present text-to-video fashions like Imagen generally generate movies the place the underlying surroundings state adjustments considerably all through the period. To build a correct trajectory planner, it will be important that the surroundings stays constant throughout all time issues. We put in force surroundings consistency in conditional video synthesis by way of offering the seen picture as further context when denoising each and every body within the synthesized video. To reach context conditioning, UniPi at once concatenates each and every intermediate body sampled from noise with the conditioned seen picture throughout sampling steps, which serves as a powerful sign to deal with the underlying surroundings state throughout time.
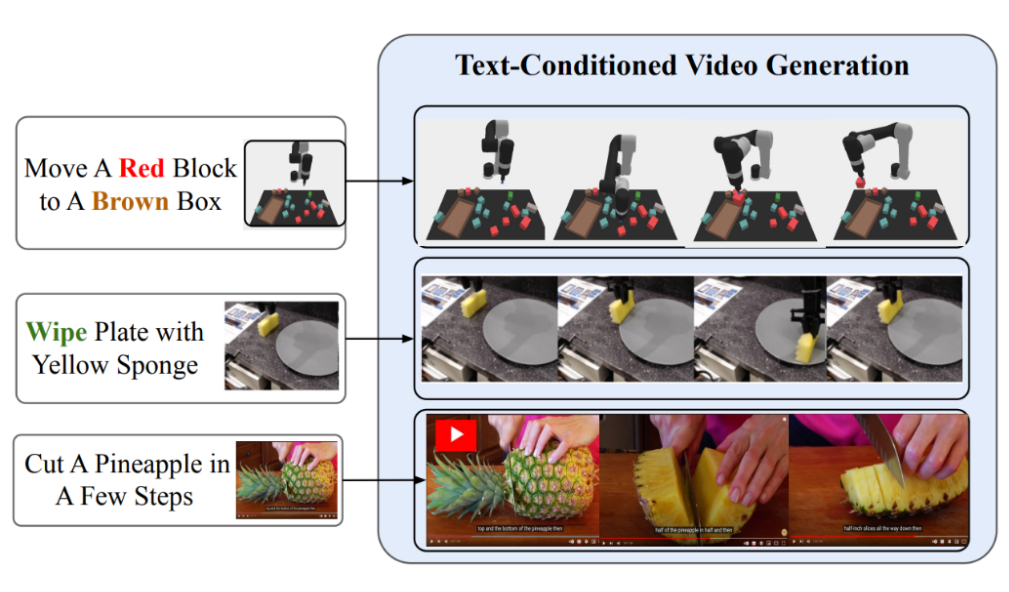 |
| Textual content-conditional video era permits UniPi to coach overall aim insurance policies on a variety of information assets (simulated, actual robots and YouTube). |
Hierarchical making plans
When setting up plans in high-dimensional environments with very long time horizons, at once producing a suite of movements to achieve a target state temporarily turns into intractable because of the exponential expansion of the underlying seek area because the plan will get longer. Making plans strategies regularly circumvent this factor by way of leveraging a herbal hierarchy in making plans. Particularly, making plans strategies first assemble coarse plans (the intermediate key frames unfold out throughout time) working on low-dimensional states and movements, which can be then delicate into plans within the underlying state and motion areas.
Very similar to making plans, our conditional video era process shows a herbal temporal hierarchy. UniPi first generates movies at a rough point by way of in moderation sampling movies (âabstractionsâ) of desired agent conduct alongside the time axis. UniPi then refines the movies to constitute legitimate conduct within the surroundings by way of super-resolving movies throughout time. In the meantime, coarse-to-fine super-resolution additional improves consistency by means of interpolation between frames.
 |
| Given an enter statement and textual content instruction, we plan a suite of pictures representing agent conduct. Photographs are transformed to movements the usage of an inverse dynamics type. |
Versatile behavioral modulation
When making plans a series of movements for a given sub-goal, one can readily incorporate exterior constraints to modulate a generated plan. Such test-time adaptability can also be applied by way of composing a probabilistic prior incorporating homes of the specified plan to specify desired constraints around the synthesized motion trajectory, which could also be suitable with UniPi. Particularly, the prior can also be specified the usage of a realized classifier on photographs to optimize a selected project, or as a Dirac delta distribution on a selected picture to steer a plan in opposition to a selected set of states. To coach the text-conditioned video era type, we make the most of the video diffusion set of rules, the place pre-trained language options from the Textual content-To-Textual content Switch Transformer (T5) are encoded.
Process-specific motion adaptation
Given a suite of synthesized movies, we teach a small task-specific inverse dynamics type to translate frames into a suite of low-level keep an eye on movements. That is impartial from the planner and can also be finished on a separate, smaller and probably suboptimal dataset generated by way of a simulator.
Given the enter body and textual content description of the present target, the inverse dynamics type synthesizes picture frames and generates a keep an eye on motion collection that predicts the corresponding long term movements. An agent then executes inferred low-level keep an eye on movements by means of closed-loop keep an eye on.
Features and analysis of UniPi
We measure the duty luck price on novel language-based targets, and in finding that UniPi generalizes smartly to each observed and novel mixtures of language activates, in comparison to baselines reminiscent of Transformer BC, Trajectory Transformer (TT), and Diffuser.
 |
| UniPi generalizes smartly to each observed and novel mixtures of language activates in Position (e.g., âposition X in Yâ) and Relation (e.g., âposition X to the left of Yâ) duties. |
Beneath, we illustrate generated movies on unseen mixtures of targets. UniPi is in a position to synthesize a various set of behaviors that fulfill unseen language subgoals:
 |
| Generated movies for unseen language targets at examine time. |
Multi-environment switch
We measure the duty luck price of UniPi and baselines on novel duties no longer observed right through practicing. UniPi once more outperforms the baselines by way of a big margin:
 |
| UniPi generalizes smartly to new environments when educated on a suite of various multi-task environments. |
Beneath, we illustrate generated movies on unseen duties. UniPi is additional in a position to synthesize a various set of behaviors that fulfill unseen language duties:
 |
| Generated video plans on other new examine duties within the multitask environment. |
Actual global switch
Beneath, we additional illustrate generated movies given language directions on unseen actual photographs. Our way is in a position to synthesize a various set of various behaviors which fulfill language directions:
 |
The usage of cyber web pre-training permits UniPi to synthesize movies of duties no longer observed right through practicing. By contrast, a type educated from scratch incorrectly generates plans of various duties:
 |
To guage the standard of movies generated by way of UniPi when pre-trained on non-robot information, we use the Fréchet Inception Distance (FID) and Fréchet Video Distance (FVD) metrics. We used Contrastive Language-Symbol Pre-training ratings (CLIPScores) to measure the language-image alignment. We display that pre-trained UniPi achieves considerably upper FID and FVD ratings and a greater CLIPScore in comparison to UniPi with out pre-training, suggesting that pre-training on non-robot information is helping with producing plans for robots. We document the CLIPScore, FID, and VID ratings for UniPi educated on Bridge information, with and with out pre-training:
| Type (24×40) | Â Â | Â Â | CLIPScore â | Â Â | Â Â | FID â | Â Â | Â Â | FVD â | Â Â | Â Â |
| No pre-training |   |   | 24.43 ± 0.04 |   |   | 17.75 ± 0.56 |   |   | 288.02 ± 10.45 |   |   |
| Pre-trained |   |   | 24.54 ± 0.03 |   |   | 14.54 ± 0.57 |   |   | 264.66 ± 13.64 |   |   |
| The usage of present cyber web information improves video plan predictions beneath all metrics regarded as. |
The way forward for large-scale generative fashions for resolution making
The certain result of UniPi level to the wider route of the usage of generative fashions and the wealth of knowledge on the net as robust gear to be informed general-purpose resolution making techniques. UniPi is just one step in opposition to what generative fashions can deliver to resolution making. Different examples come with the usage of generative basis fashions to supply photorealistic or linguistic simulators of the sector through which synthetic brokers can also be educated indefinitely. Generative fashions as brokers too can discover ways to have interaction with advanced environments such because the cyber web, in order that a lot broader and extra advanced duties can ultimately be computerized. We look ahead to long term analysis in making use of internet-scale basis fashions to multi-environment and multi-embodiment settings.
Acknowledgements
Weâd love to thank all ultimate authors of the paper together with Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B. Tenenbaum, Dale Schuurmans, and Pieter Abbeel. We want to thank George Tucker, Douglas Eck, and Vincent Vanhoucke for the comments in this publish and at the authentic paper.