Artificial Intelligence (ML) is a big subset of expert system that studies techniques for constructing learning-capable algorithms. ( Wikipedia Meaning)
You can likewise discover such a meaning. Artificial intelligence is a branch of AI that checks out techniques that permit computer systems to enhance their efficiency based upon experience.
The very first self-learning algorithm-based program was established by Arthur Samuel in 1952 and was developed to play checkers. Samuel likewise provided the very first meaning of the term “artificial intelligence”: it is “the field of research study in the advancement of makers that are not preprogrammed.”
In 1957, the very first neural network design was proposed that carries out artificial intelligence algorithms comparable to contemporary ones. A range of artificial intelligence systems are presently being established for usage in future innovations such as the Web of Things, the Industrial Web of Things, the principle of a “clever” city, the production of uncrewed cars, and numerous others.

The list below truths proof the reality that terrific hopes are now pinned on artificial intelligence: Google thinks that quickly its items “will no longer be the outcome of standard shows– they will be based upon artificial intelligence”; New items like Apple’s Siri, Facebook’s M, and Amazon’s Echo have actually been constructed utilizing artificial intelligence. In 1957, the very first neural network design was proposed that carries out artificial intelligence algorithms comparable to contemporary ones. A range of artificial intelligence systems are presently being established for usage in future innovations such as the Web of Things, the Industrial Web of Things, the principle of a “clever” city, the production of uncrewed cars, and numerous others.
Now that we have actually found out what artificial intelligence is let’s take a look at how to construct a maker discovering system so that it works efficiently for a particular company’s particular objectives.
- What is a maker discovering pipeline?
- Design preparation procedure
- Artificial intelligence pipeline in production
- Artificial intelligence design re-training pipeline
- Tools for artificial intelligence pipeline production
- Why is the device discovering pipeline essential?
What is a maker discovering pipeline?
A maker discovering pipeline (or system) is a technical facilities utilized to handle and automate artificial intelligence procedures. The reasoning of constructing a system and picking what is needed for this depends just on artificial intelligence tools– pipeline management engineers for training, design positioning, and management throughout production.
A maker discovering design is an outcome acquired by training a maker algorithm utilizing information. After training is total, the design produces an output when input information is participated in it. For instance, a forecasting algorithm develops a forecasting design. Then, when information is participated in the predictive design, it releases a projection based upon the information utilized to train the design.
There is a clear difference in between training and running artificial intelligence designs in production. However, before we take a look at how device discovering operate in a production environment, let’s very first take a look at the actions associated with preparing a design.
Design preparation procedure
When establishing a design, information engineers operate in some advancement environment particularly developed for artificial intelligence, such as Python, R, and so on. And they can train and check the designs in the very same “sandboxed” environment while composing reasonably little code. It is outstanding for fast-to-market interactive models.
The device discovering design preparation procedure includes 6 actions. This structure represents the easiest method to procedure information through artificial intelligence.
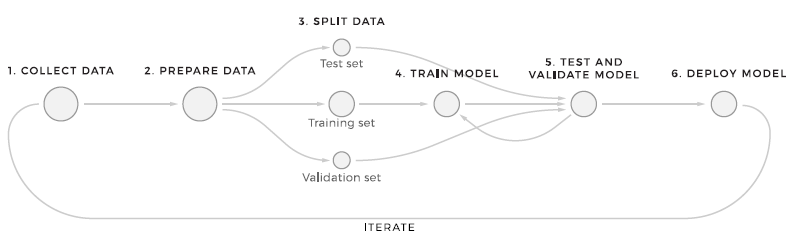
- Gathering the needed information. The very first thing that any ML workflow begins with is sending out inbound information to the shop. No changes are used to the information at this moment, which enables you to keep the initial information set the same.
NoSQL databases appropriate for keeping big quantities of quickly altering structured and/or disorganized information since they do not include schemas. They likewise use dispersed, scalable, reproduced information storage. - Information preparation. As quickly as the information goes into the system, the dispersed pipeline searches for distinctions in format, patterns, information accuracy, and which information is missing out on and damaged and fixes any abnormalities. This action likewise consists of the function advancement procedure. There are 3 primary phases in the function pipeline: extract, change, and choose.

Preparing the information is the hardest part of an ML task. Executing the ideal style patterns is important. Likewise, do not forget that they are transformed numerous times. This is frequently done by hand, specifically, format, cleansing, labeling, and improving the information so that the information quality for future designs is appropriate. After preparing the information, information researchers start to create functions. Functions are information worths that the design will utilize in both training and production.
Each function set is designated a distinct identifier to guarantee consistency of performance - Information separation. At this phase, it is needed to divide the information, to start with, to teach the design and later on inspect how it deals with brand-new information. An artificial intelligence system’s main objective is to utilize a precise design based upon the quality of anticipating patterns on information that it has actually not formerly trained on. There are numerous methods for this, such as utilizing basic ratios, sequentially, or arbitrarily.
- Design Knowing: Here, in turn, it deserves utilizing a subset of the information so that the device discovering algorithm acknowledges particular patterns. The design training pipeline works offline and can be set off by time and by the occasion. It includes a library of training design algorithms (direct regression, k-means, choice trees, and so on). The training of the design must be performed, taking into consideration the resistance to mistakes.
- Checking and Recognition: Assessing design efficiency includes utilizing a test subset of the information to get a much deeper understanding of how precise the forecast is. By comparing outcomes in between tests, the design can be tuned/modified/ trained on various information. The training and assessment actions are duplicated numerous times till the design reaches an appropriate portion of right forecasts.
- Implementation: Once the picked design is produced, it is normally released and embedded in the choice making structure. More than one design can be released to guarantee a safe shift in between the old and brand-new designs.

Intrigued in executing a maker discovering pipeline into your working circulation?
Artificial intelligence pipeline in production
When the design training is done, the next action is to release it to the production environment, where the design will make its forecasts on the genuine information, materializing industrial impacts. The essential action here is release, however efficiency tracking is likewise something that requires to be done regularly.
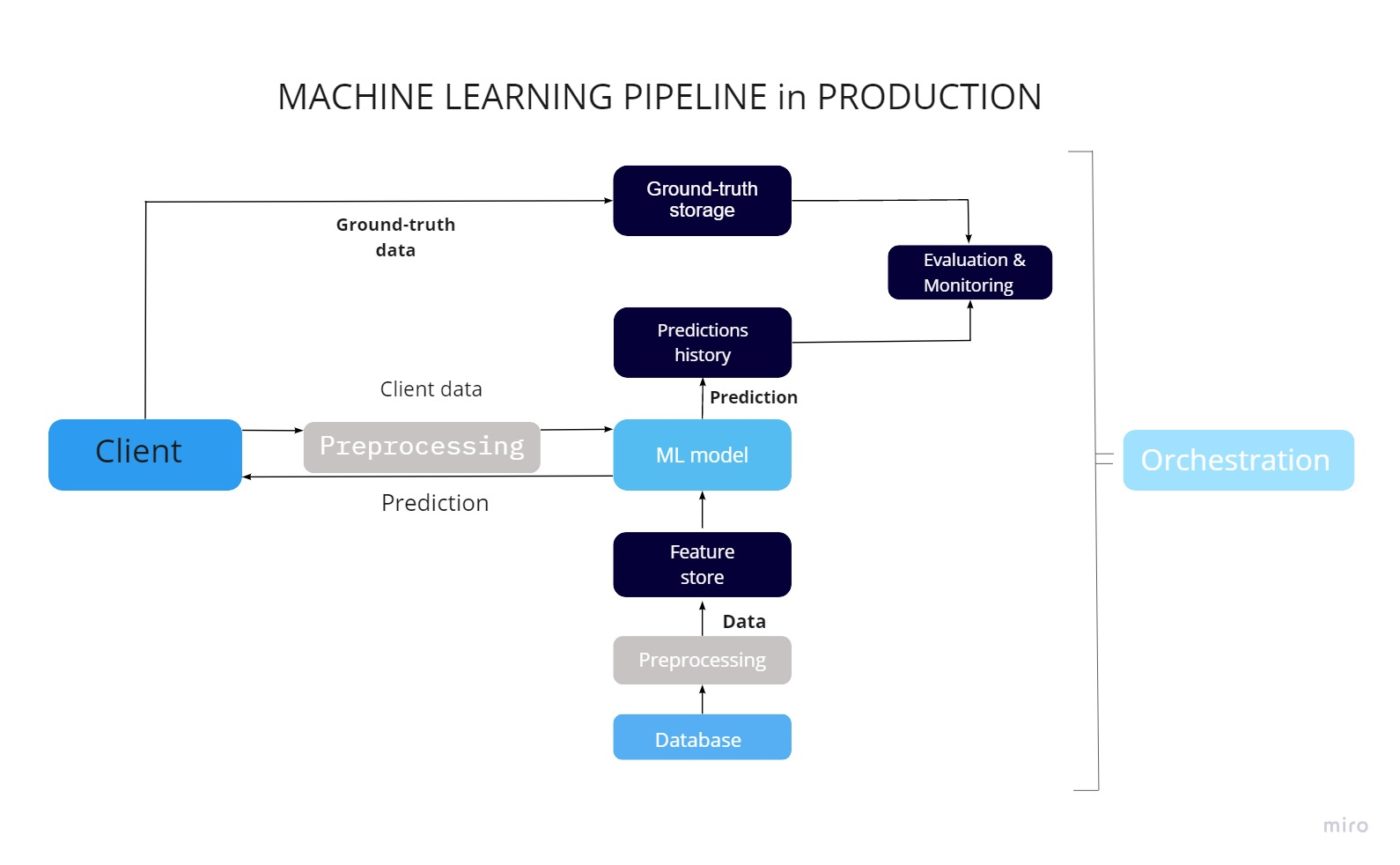
Control over the designs, in addition to their efficiency, is important for the device discovering pipeline. Let’s have a look at the basic architecture, divide the procedure into particular actions, and make an introduction of the primary tools utilized for specific operations. Please keep in mind that there are numerous kinds of artificial intelligence systems, and we are talking here based upon our experience. We hope that you will have a basic concept of how artificial intelligence systems work by the end.
Access to the design forecast information through the application
Let’s presume one has an application that either connects with the customers or other parts of the system. In this case, access to the information will be possible when specific input information will be offered. For instance, the comparable items suggestions on the popular eCom markets operate in such method, the information about all the gone to items is gathered throughout the user journey through the market, this information is sent out to the design through API and after that the action is provided with the list of items that may be intriguing for this specific customer.
Function shops and how they work
Sometimes, the information can’t be straight accessed, in this case, the function shops can assist. The example of the information that can’t be straight moved utilizing the API is the very same item suggestion system however based upon other users’ tastes. We must discuss, that the volume of such information can be rather huge, so here are 2 choices on how to supply it: batching and streaming.
Batching is essentially getting the details in parts, like the pagination. Information streaming on the other hand is information streamed on the go and can be utilized for parcel tracking, for instance, offering the evaluation based upon the right place of the shipment car.
Information preprocessing
The information originates from the application customer in a raw format. This technique enables the design to read this information; then it should be processed and transformed into functions so that the design can utilize it.
- The function shop can likewise have a devoted microservice for automated information preprocessing.
- Information preprocessor: information sent out from the application customer and function shop is formatted, functions are recovered.
- Making projections: a fter the design gets all the needed performance from the customer and the function shop, it creates a projection. It sends it to the customer and a different database for more assessment.
Saving precise information and projections
It is likewise important for us to get accurate information from the customer. Based upon them, the evaluation of the projections made by the design and for its more enhancement will be performed. This sort of details is normally kept in a database of legitimate information.
Nevertheless, it is not constantly possible to gather honest details in addition to automate this procedure. Think about an example, if a consumer bought an item from you, this is a reality and can compare the design’s forecasts. And what if a customer saw your deal, however purchased from another seller, in this case, acquiring honest details is difficult.
Design assessment and tracking
ML designs released in the production environment requires to be kept track of and assessed continuously. To make certain the design provides the very best outcomes we require to:
- Keep forecast results to be as high as possible.
- Evaluate the design efficiency.
- To have an understanding of the design requires to be trained once again.
- To have a control panel with the efficiency KPIs we have actually set.
Many open-source libraries offered for visualization are the very same as some tracking tools (MLWatcher, for instance, for Python, enables it).
Orchestration
Orchestration is the automated positioning, coordination, and management of intricate computer system systems. Orchestration explains how services must communicate with each other utilizing messaging, consisting of company reasoning and workflow.
Hence, it offers total control over the release of designs on the server, handling their operation, information circulation management, and activation of training/retraining procedures.
Orchestrators utilize scripts to schedule and carry out all of the jobs connected with a production environment’s artificial intelligence design. Popular tools utilized to manage artificial intelligence designs are Apache Air flow, Apache Beam, and Kubeflow Pipelines.
Artificial intelligence design re-training pipeline
The information on which the designs are trained are dated due to this, the precision of the projections reduces. Tracking tools can be utilized to track this procedure. When it comes to seriously low performance, it is needed to re-train the design utilizing the brand-new information. This procedure can be made automated.
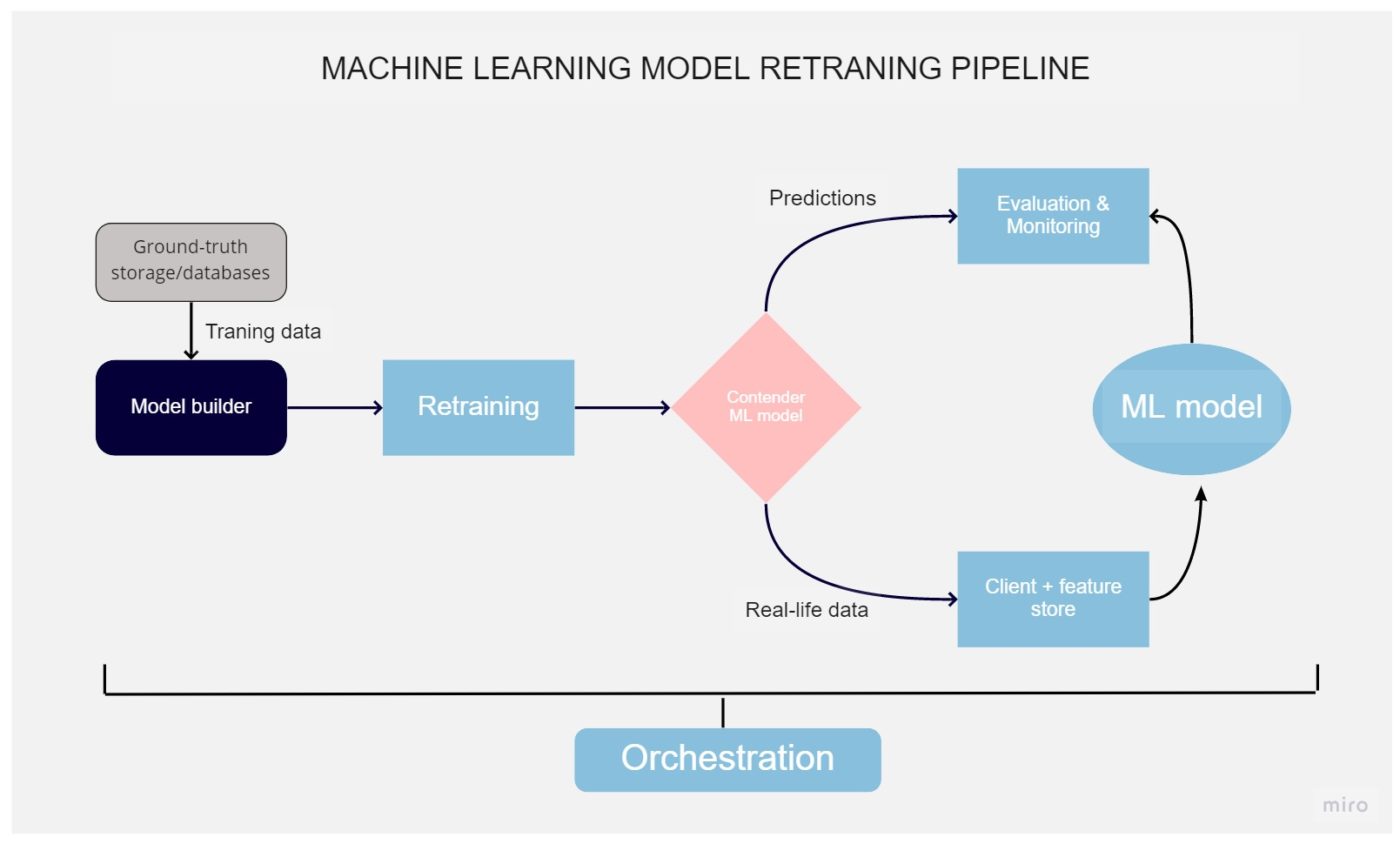
Design re-training
The like training the design, the re-training procedure is likewise an essential part of the entire life process. This procedure utilizes the very same resources, like training, going through the very same actions till the release. Still, it’s needed if the forecast precision reduced listed below the appropriate level that we keep track of utilizing the techniques discussed previously. This does not always suggest our design works bad however can take place if some brand-new functions were presented on an item that likewise requires to be consisted of in the ML design.
Re-trained design assessment
The design trained on brand-new information is developed to change the old one, however before that, it should be compared to essential and other indications, specifically precision, throughput, and so on.
This treatment is performed utilizing a distinct tool– a critic, which examines the design’s preparedness for production. It examines how precise the forecasts are, and utilizing genuine and trustworthy information, and it can just compare experienced designs with currently working designs. Showing the outcomes of the opposition design takes place utilizing keeping track of tools. If a brand-new design carries out much better than its predecessor, then it is taken into production.
Wish to know how you can take advantage of ML pipeline?
Tools for Artificial intelligence Pipeline production
Artificial Intelligence Pipeline is constantly a customized service, however some digital tools and platforms can assist you construct it. So let’s summary a few of them for a much better understanding of how they can be utilized.
| Steps For Structure Artificial Intelligence Pipeline | Tools Which Can be Utilized |
| Collecting Data | Handling the Database– PostgreSQL, MongoDB, DynamoDB, MySQL
Storage– Hadoop, Apache Glow/ Apache Flink |
| Preparing Data | The language for scripting– SAS, Python, and R.
Processing– MapReduce/ Glow, Hadoop. Information Wrangling Tools– R, Python Pandas |
| Checking Out/ Envisioning the Information to discover the patterns and patterns | Python, R, Matlab, and Weka. |
| Designing the information to do the forecasts | Artificial intelligence algorithms– Monitored, Not Being Watched, Support, Semi-Supervised and Semi-unsupervised knowing.
Libraries– Python (Scikit find out)/ R (CARET) |
| Translating the outcome | Information Visualization Tools– ggplot, Seaborn, D3.JS, Matplotlib, Tableau |
Why is the device discovering pipeline essential?
Automating the design life process phases is the most essential function of why the device discovering pipeline is utilized. With the brand-new training information, a workflow begins with information recognition, preprocessing, design training, analysis, and release. Carrying out all these actions by hand is pricey, and there is a possibility of making errors. Next, we wish to take a look at the advantages of utilizing artificial intelligence pipelines:
- # 1 Capability to concentrate on brand-new designs without supporting existing designs Automated device discovering pipelines negate the requirement to keep existing designs, which conserves time and does not require to run scripts to preprocess the training information by hand.
- # 2 Avoiding mistakes In manual device discovering workflows, a typical mistake source is altering the preprocessing phase after design training. To prevent this, you can release the design with processing guidelines that are various from those trained. These mistakes can be avoided by utilizing automatic workflows.
- # 3 Standardization Standardized device discovering pipelines boost the information researcher group’s experience and allow you to link to work and rapidly discover the very same advancement environments. This enhances performance and decreases the time invested establishing a brand-new task.
Business case for pipelines
The execution of automated device discovering pipelines causes enhancements in 3 locations:
- More time to establish brand-new designs
- Simpler procedures for upgrading existing designs
- Less time invested playing designs.
All these elements will lower task expenses, and besides, it will assist discover possible predispositions in datasets or trained designs. Determining predisposition can avoid damage to individuals engaging with the design.
To conclude
Artificial intelligence pipelines supply numerous advantages, however not every information task requires a pipeline. If you wish to try out how information works, then pipelines are ineffective in these cases. Nevertheless, as quickly as the design has users (for instance, it will be utilized in an application), it will need continuous updates and fine-tuning.
Pipelines likewise end up being more crucial as the device discovering task grows. If the dataset or resource requirements are big, the methods we talk about to make it simple to scale the facilities. If repeatability is important, this is achieved through the device discovering pipelines’ automation and audit path.
Get a complimentary assessment on how you can improve business procedures with ML pipeline.